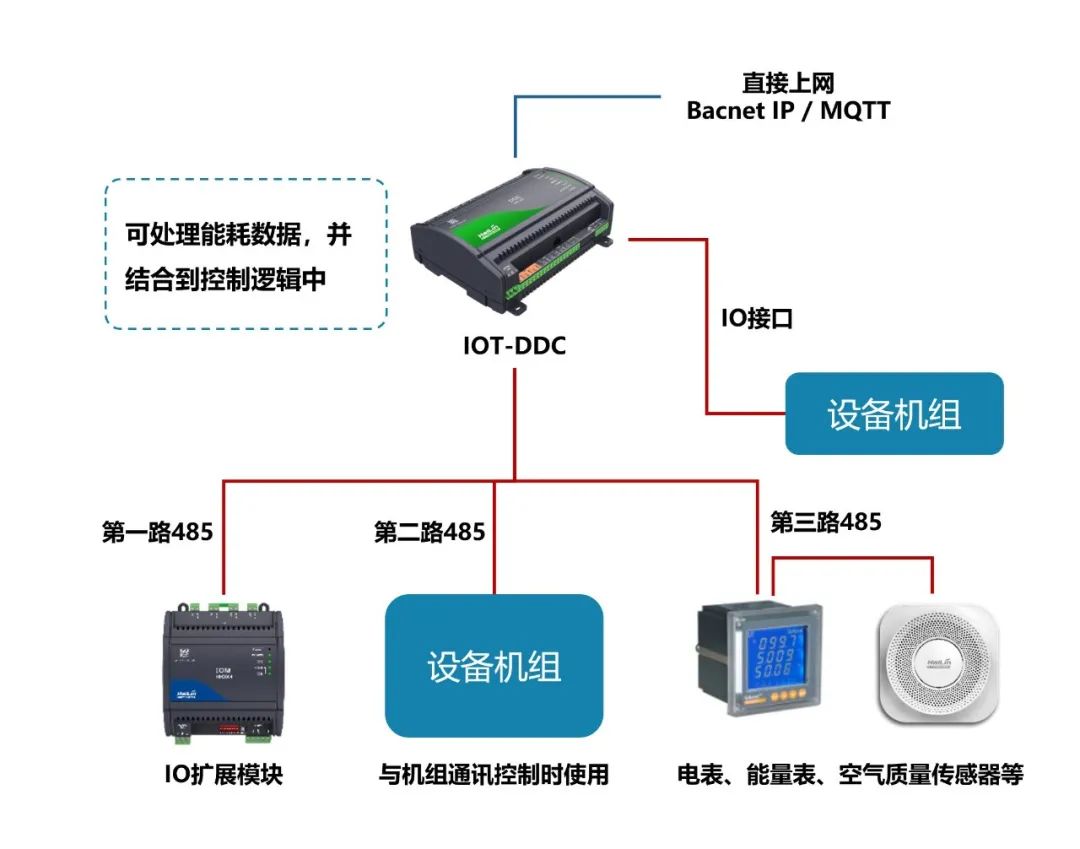
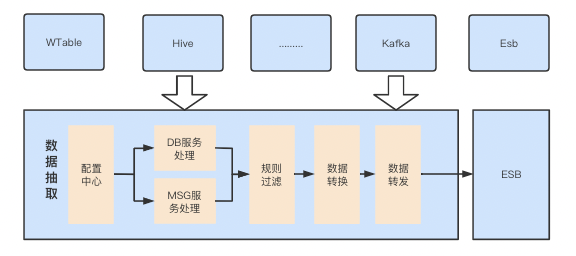
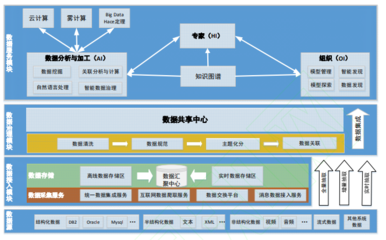
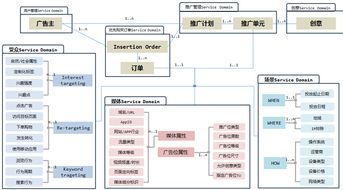
2008日志清理與SQL Server DataWorks數(shù)據(jù)集成 歸檔日志至MaxCompute進(jìn)行離線(xiàn)分析的高效方案
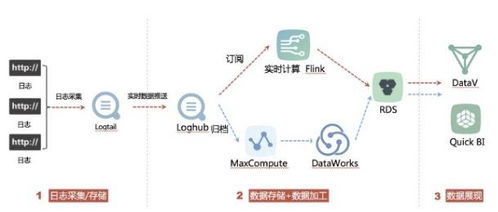
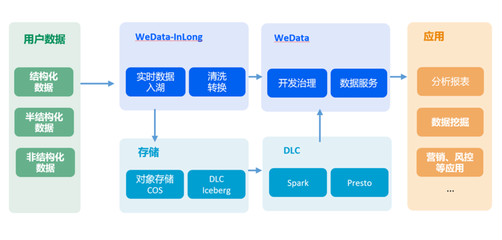
在實(shí)際的數(shù)據(jù)運(yùn)維中,隨著業(yè)務(wù)系統(tǒng)數(shù)據(jù)的不斷增長(zhǎng),數(shù)據(jù)庫(kù)日志(如SQL Server的事務(wù)日志、錯(cuò)誤日志或自定義應(yīng)用日志)會(huì)迅速膨脹,導(dǎo)致存儲(chǔ)空間緊張和性能下降。尤其是在金融、電商或政府機(jī)構(gòu)等對(duì)數(shù)據(jù)合規(guī)性有嚴(yán)格要求的場(chǎng)景中,日志的歸檔與離線(xiàn)分析是不可或缺的一環(huán)。為了解決這一問(wèn)題,本文提出一套基于DataWorks數(shù)據(jù)集成服務(wù)的解決方案,將2008年歷史的業(yè)務(wù)日志從SQL Server清理并歸檔至阿里云MaxCompute,實(shí)現(xiàn)日志的低成本存儲(chǔ)與長(zhǎng)效離線(xiàn)分析。\n\n一、問(wèn)題背景\n在大數(shù)據(jù)平臺(tái)上,SQL Server常作為在線(xiàn)業(yè)務(wù)庫(kù)使用,每隔兩天記錄超2000萬(wàn)條日志條目。如果不進(jìn)行歸檔,存儲(chǔ)成本直接體現(xiàn)在PB級(jí)的磁盤(pán)占用上;繁多的日志查詢(xún)直接影響交易系統(tǒng)性能,而保留了歷史日志(如清空自增3號(hào)流程表的操作)也很難在線(xiàn)動(dòng)態(tài)分析。邏輯相對(duì)明確的需求轉(zhuǎn)化為作業(yè)流程——清理效率縮短48小時(shí)內(nèi),保證操作嚴(yán)格自動(dòng)化且遺留監(jiān)控易忽略的快子期聯(lián)不可用的正確。尤其是2008年前的舊角色歸檔機(jī)制過(guò)期后更不易獲取狀態(tài)固化下的解析機(jī)會(huì)。所以在實(shí)驗(yàn)方案包含自動(dòng)歸類(lèi)管理過(guò)程中,我們的客戶(hù)將DataWorks的批量數(shù)位版本項(xiàng)目按照異步Pipeline系統(tǒng)每天回流至開(kāi)發(fā)庫(kù)存且打散冷熱整理之后的DWD庫(kù)傳輸?shù)綄?duì)象平臺(tái)Maxcompute。\n\n二、歸檔目標(biāo)厘定和實(shí)施思路
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.heqinghuanjingyouxiangongsi.cn/product/12.html
更新時(shí)間:2026-06-19 13:45:42